【Magic xpa 連載最新号のご案内】 2026年4月6日

Magic xpa 開発者ユーザの皆様へ
【1】 Magic xpa 連載のご案内
------------------------------------------------
本日、Magic xpa の連載、「Magic xpa で作るイベントドリブン型プログラム」の第217回目「部分一致検索の高速化ノウハウ」を連載コーナーにアップいたしました。
https://www.tandacomp.com/ホーム/magic-連載コーナー
画面1は、日本郵便が公開している全国郵便番号データを簡略化して、テーブル表示したものです(画面1)。
※テストを行うために、「都道府県名」と「市区町村名」と「町域名」を結合して、ひとつの「住所」項目としています。
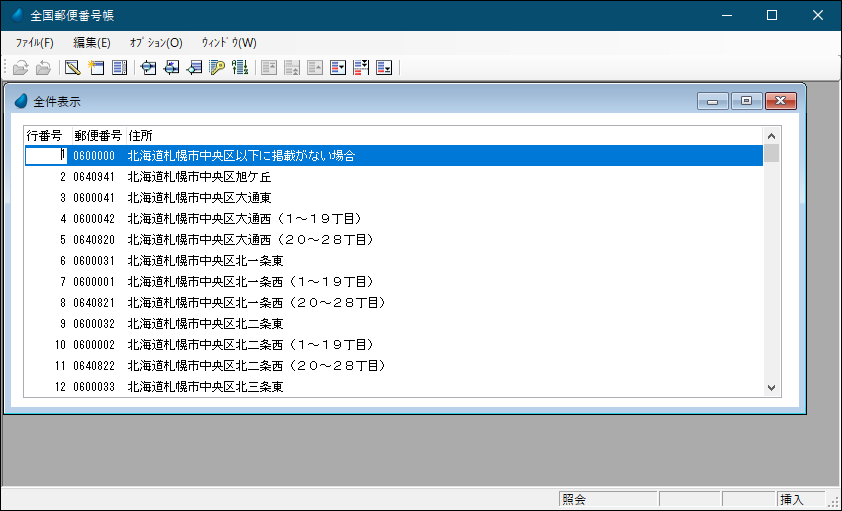
画面1 全国郵便番号データ
このテーブルには、全部で約12万4千件の住所レコードがあります(画面2)。
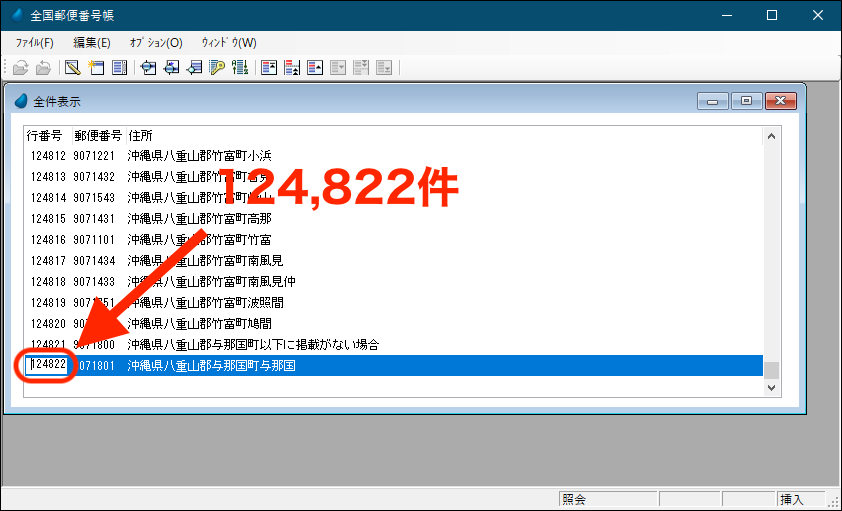
画面2 約12万4千件のレコード
このテーブルを用いて、Magicでの検索能力を試してみたいと思います。ただし、文字列の先頭一致では、インデックスが効いてデータは一瞬で検索されてしますので能力のテストにはなりません。したがってここでは、インデックスが使えない、途中文字列の部分一致検索を用いてその能力を試してみたいと思います。
例として、わざと負荷を掛けるために、12万4千件の全国郵便番号データから、「住所の途中に、"北新宿" または "南新宿" という文字列が含まれるものを探す」という複合検索を行ってみたいと思います。先頭一致ではなく、部分一致の、しかも複合検索です。かなりの負荷が掛かるはずです。
まずは、dbMAGIC V4(1989年頃)からある、古い関数と古い方式を用いて検索プログラムを作成してみます。
下図がそのプログラムの実行結果です。「北新宿」または「南新宿」を含むレコードが3件見つかり、検索に17秒かかりました(画面3)。
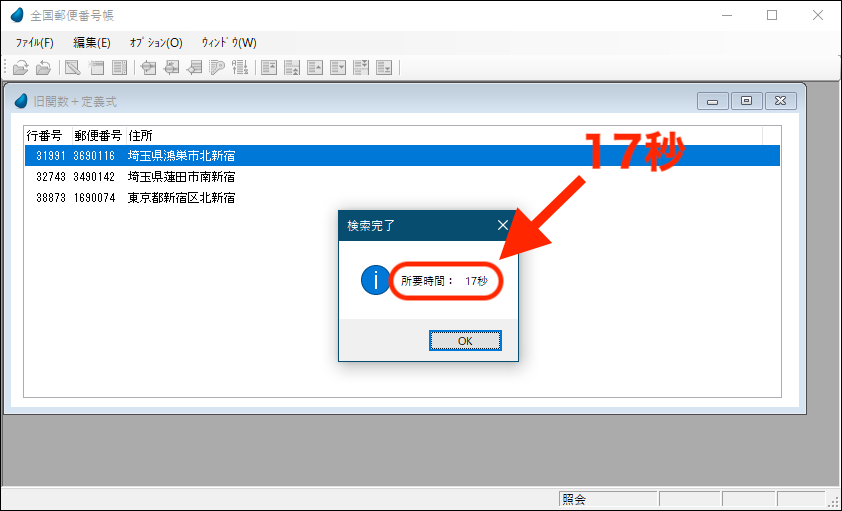
画面3 検索に17秒かかった
今度はこれを、Magic xpaの新方式を用いて、まったく同じ関数を用いた検索を行ってみます。
下図がその実行結果です。わずか5秒で終わりました。37年前と同じ関数を使用しているにもかかわらず、旧方式の3倍以上のパフォーマンスが得られたわけです(画面4)。
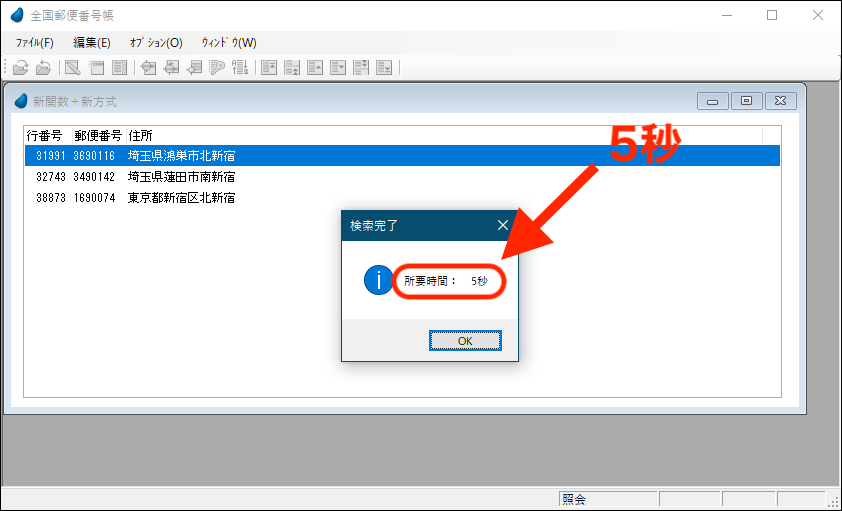
画面4 わずか5秒で検索完了!
なお、このテストは10年以上前に購入したPC(Celeron 1.10GHz)で行っていますので、パフォーマンスはかなり悪いほうです。最新のPCであれば、検索に要する時間は1秒〜2秒ほどになるはずです。
繰り返しますが、このテストはインデックスを用いた先頭一致の検索ではなく、途中文字列の部分一致検索です。それにもかかわらず、このパフォーマンスです。古い方式のプログラムを見直さない手は無いと言えます。事務処理現場のユーザから喜ばれること、請け合いです。
今回は、その部分一致検索の高速化ノウハウについてお伝えしてまいります。
なお、本号の解説は、過去記事の統合改訂版ともなりますので、過去記事も併せてお読みください(以降、本編に続く)。
目次
1. 12万4千件のレコードで部分一致検索
2. まずは伝統的な方法による検索
3. 新方式による検索で3倍の速度が!
4. 伝統的な関数を用いて旧方式で検索
5. 同じ伝統的な関数を新方式で実行
6. 速度の違いの要因をログで確認
7. 新しい関数を用いて旧方式で検索
8. 新しい関数を用いて新方式で検索
9. 速度の違いをログで確認
10. メニューの拡張検索を使用した場合
11. それぞれの検索実行結果をログで確認
12. 速度向上に関連する過去記事のリスト
次回は、「所要時間計測プログラムの作り方」をお送りします。
購読期間中は現在掲載中の過去記事をすべて読むことができます。
皆様のお越しをお待ちいたしております。
サインインしてコメントを残してください。
コメント
0件のコメント